Vishal Anand1,3 Raksha Ramesh1,2 Boshen Jin1,2 Ziyin Wang1,2 Xiaoxiao Lei2 Ching-Yung Lin1,2
Raksha Ramesh1,2 Vishal Anand1,3 Ziyin Wang1,2 Tianle Zhu1 Wenfeng Lyu1 Serena Yuan1 Ching-Yung Lin1,2
Vishal Anand1,2 Raksha Ramesh1 Ziyin Wang1,2 Yijing Feng1 Jiana Feng1 Wenfeng Lyu1 Tianle Zhu1 Serena Yuan1 Ching-Yung Lin1,2
1Columbia University, New York, NY, USA
2Graphen AI, New York, NY, USA
3Microsoft, Redmond, WA, USA
Abstract
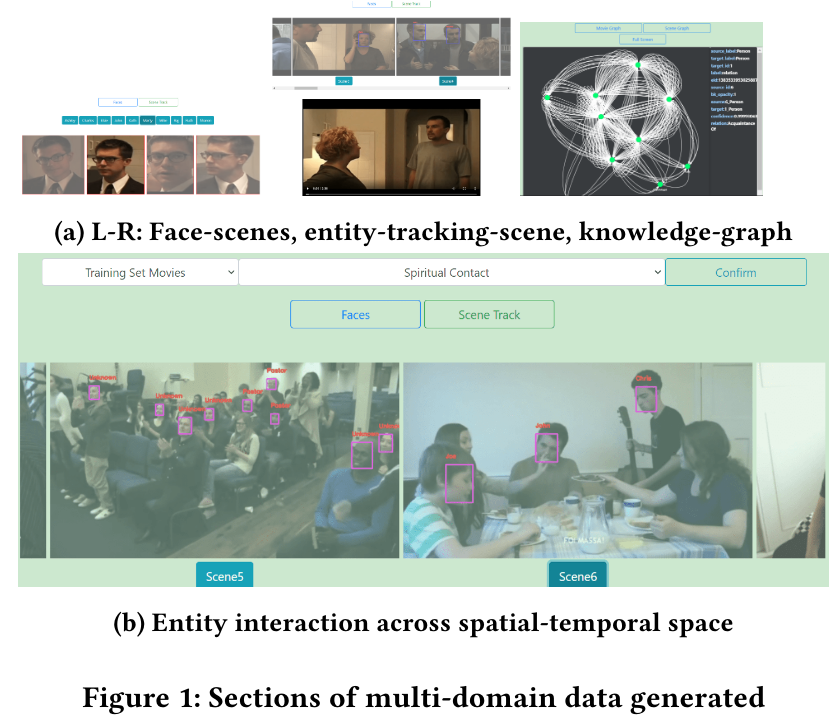
The natural language processing community has had a major interest in auto-regressive and span-prediction based language models recently, while knowledge graphs are often referenced for common-sense based reasoning and fact-checking models. In this paper, we present an equivalence representation of span-prediction based language models and knowledge-graphs tobetter leverage recent developments of language modelling for multi-modal problem statements. Our method performed well, especially with sentiment understanding for multi-modal inputs, anddiscovered potential bias in naturally occurring videos when compared with movie-data interaction-understanding. We also release adataset of an auto-generated questionnaire with ground-truths consisting of labels spanning across 120 relationships, 99 sentiments,and 116 interactions, among other labels for finer-grained analysis of model comparisons in the community.
Cite
ACM Multimedia 2021:
@inbook{10.1145/3474085.3479220,
author = {Anand, Vishal and Ramesh, Raksha and Jin, Boshen and Wang, Ziyin and Lei, Xiaoxiao and Lin, Ching-Yung},
title = {MultiModal Language Modelling on Knowledge Graphs for Deep Video Understanding},
year = {2021},
isbn = {9781450386517},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3474085.3479220},
booktitle = {Proceedings of the 29th ACM International Conference on Multimedia},
pages = {4868–4872},
numpages = {5}
}
ACM Multimedia 2020:
@inproceedings{10.1145/3394171.3416305,
author = {Anand, Vishal and Ramesh, Raksha and Wang, Ziyin and Feng, Yijing and Feng, Jiana and Lyu, Wenfeng and Zhu, Tianle and Yuan, Serena and Lin, Ching-Yung},
title = {Story Semantic Relationships from Multimodal Cognitions},
year = {2020},
isbn = {9781450379885},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3394171.3416305},
doi = {10.1145/3394171.3416305},
booktitle = {Proceedings of the 28th ACM International Conference on Multimedia},
pages = {4650–4654},
numpages = {5},
keywords = {natural language processing, information extraction, speaker identification, video understanding, lexical semantics, video to text},
location = {Seattle, WA, USA},
series = {MM '20}
}
ICMI Workshop 2020:
@inproceedings{10.1145/3395035.3425641,
author = {Ramesh, Raksha and Anand, Vishal and Wang, Ziyin and Zhu, Tianle and Lyu, Wenfeng and Yuan, Serena and Lin, Ching-Yung},
title = {Kinetics and Scene Features for Intent Detection},
year = {2020},
isbn = {9781450380027},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3395035.3425641},
doi = {10.1145/3395035.3425641},
booktitle = {Companion Publication of the 2020 International Conference on Multimodal Interaction},
pages = {135–139},
numpages = {5},
keywords = {natural language processing, neural networks, computer vision, activity recognition, object recognition, information extraction, scene detection, video understanding, multi-modal fusion},
location = {Virtual Event, Netherlands},
series = {ICMI '20 Companion}
}
Contact
- Vishal Anand va2361 AT columbia DOT edu
- Raksha Ramesh raksha AT graphen DOT ai
- Ching-Yung Lin c.lin AT columbia DOT edu, cylin AT graphen DOT ai